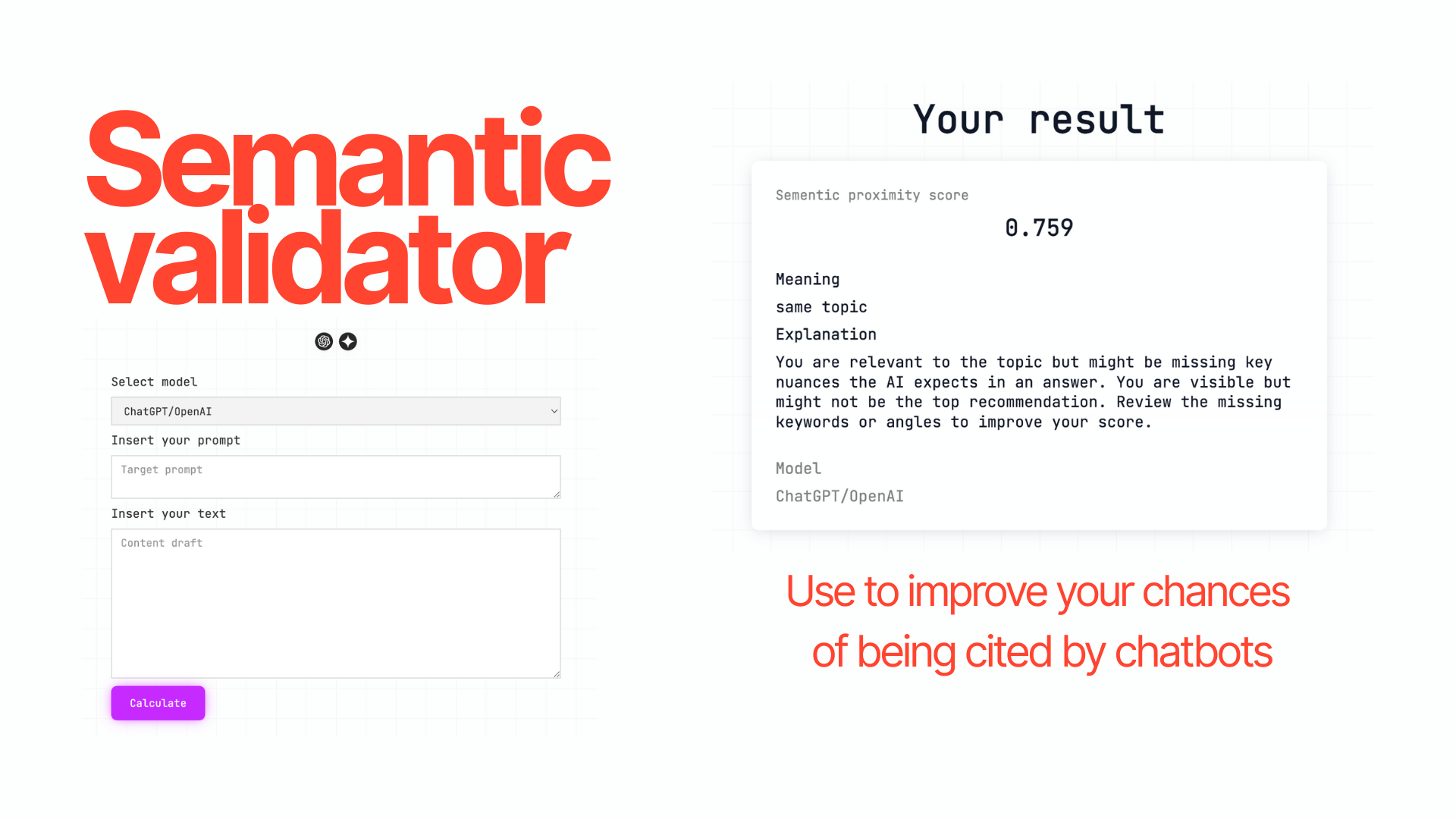
Solutions
Platform

Modern embedding models from different providers are increasingly used interchangeably for semantic search, retrieval, and clustering. At Turbine, we use embeddings to measure content similarity and support content development. However, little empirical work evaluates whether these models induce similar similarity structures over the same text corpora. This study aims to quantify cross-model semantic alignment by comparing neighborhood agreement and rank consistency across embedding models trained with different architectures and objectives. Cross-model embedding comparisons typically rely on performance metrics rather than direct geometric or ranking agreement, leaving a gap in understanding how models align at the representation level.
We evaluate 1000 text domains to capture varying levels of semantic structure:
All texts are under 1,000 tokens to ensure compatibility across models. This domain diversity allows assessment of how semantic agreement varies with structure, factual density, and lexical.
The following embedding models are evaluated:
SBERT: A sentence-transformer model trained with supervised similarity objectives.
OpenAI Embeddings: A large proprietary embedding model optimized for semantic retrieval.
Gemini Embeddings: A proprietary embedding model with a similar retrieval-oriented objective but independent training.
These models differ in architecture, scale, and training data, making direct comparison non-trivial.
For each dataset:
All texts are embedded using each model.
Pairwise cosine similarity matrices are computed per model.
Two complementary alignment metrics are evaluated:
Rank Correlation (Spearman ρ): Measures global agreement in similarity ordering across all text pairs.
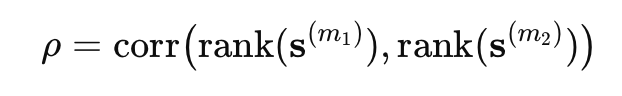
Overlap at top-K: Measures overlap of top-K nearest neighbors between models, capturing local semantic consistency.
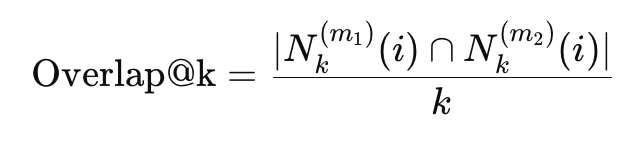
Across all domains:
OpenAI ↔ Gemini consistently shows the highest alignment in both Agreement@K and rank correlation.
SBERT ↔ proprietary models exhibit lower but still strong agreement.
Structured domains (historical, medical, paraphrased texts) produce higher alignment than random or loosely structured text.
Overlap at top-K decreases mildly as K increases, reflecting increasing semantic ambiguity in larger neighborhoods.
Overall, Overlap at top-K values exceed 0.6 in all settings, indicating substantial cross-model semantic consistency. However, for embedding-based applications in GEO, including brand semantic gap analysis, content clustering etc., appropriate embedding models should be selected for each LLM.
How to read results:
Spearman's rank correlation results:
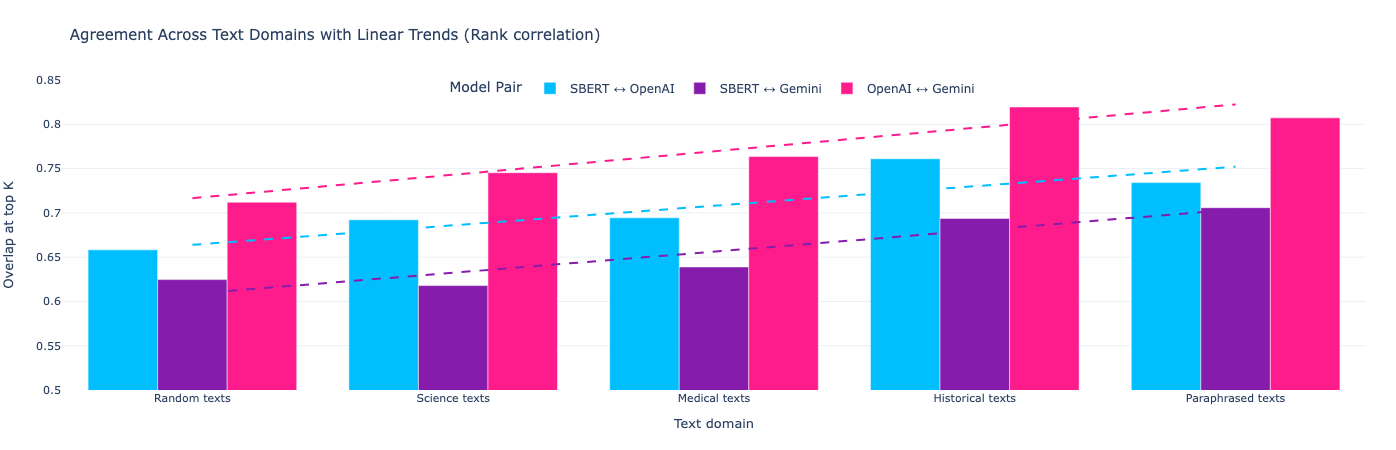
Across all evaluated domains, embedding models demonstrate substantial agreement in similarity ranking, with OpenAI and Gemini showing the strongest alignment. Rank correlation increases for structured and paraphrased texts, suggesting convergence on well-defined semantic cues. In contrast, SBERT exhibits systematically lower alignment with proprietary models, reflecting differences in training scale and objectives. Overall, the results indicate that modern embedding models share a robust global semantic ordering, particularly for information-dense domains.
Overlap at top-K across embedding model pairs results:
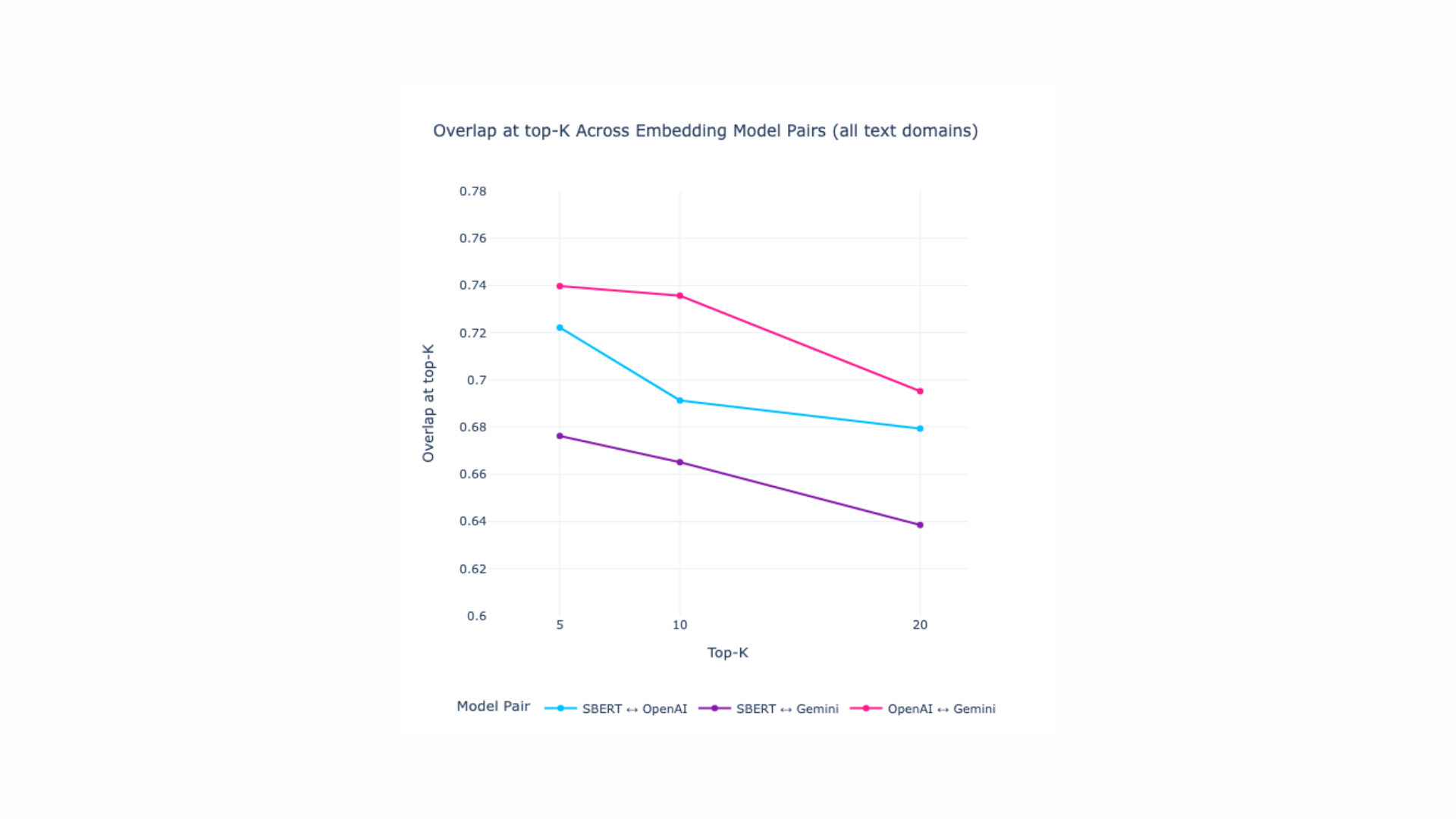
Overlap at top-K across embedding model pairs results (different text domains):
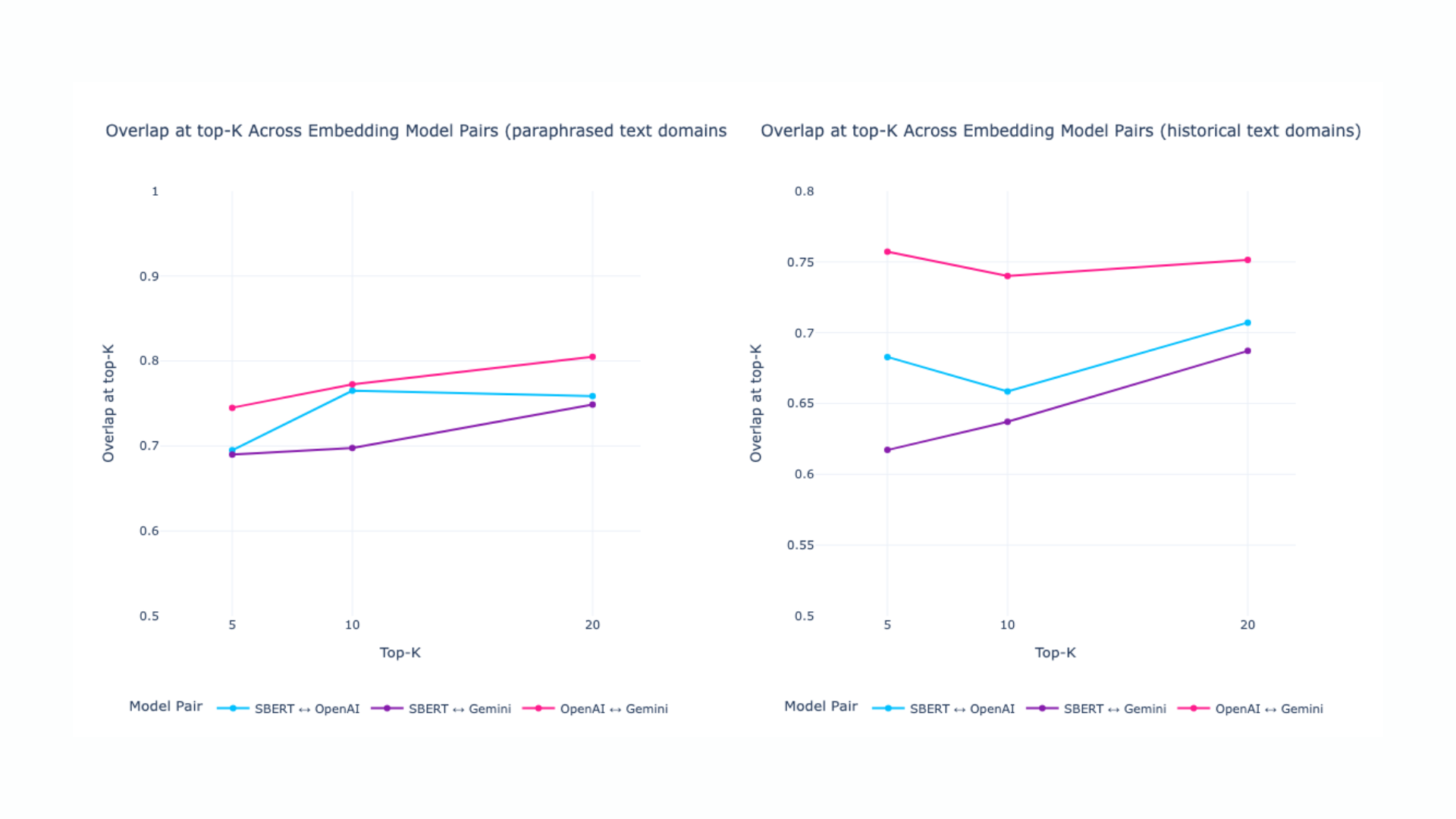
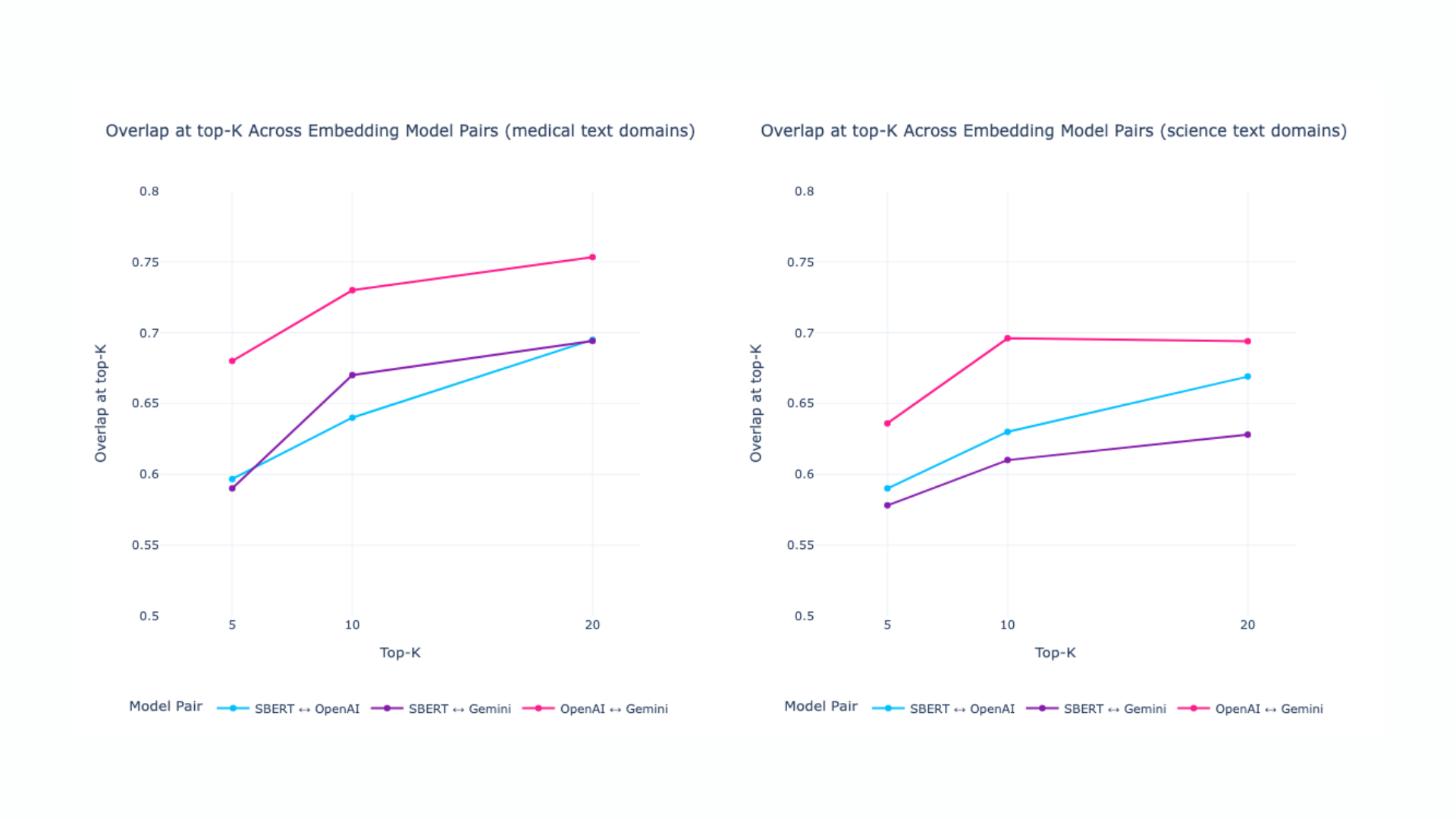
Disagreements are most common in:
SBERT more frequently diverges in ranking fine-grained neighbors, while proprietary models show stronger internal consistency.
The observed alignment between embedding models has direct implications for Generative Engine Optimization (GEO) and AI-driven content visibility. Since modern LLM systems rely heavily on embedding-based retrieval, clustering, and relevance ranking, the choice of embedding model materially affects how content is indexed, grouped, and surfaced by generative systems.
First, the strong agreement between proprietary embedding models suggests that well-structured, factual content is likely to be consistently interpreted across multiple AI platforms. This implies that content optimized for semantic clarity, topical focus, and explicit entity relationships has a higher probability of being retrieved and referenced by different generative engines, improving cross-platform AI visibility.
Second, the lower but still substantial alignment between SBERT and proprietary models highlights that embedding choice matters for GEO diagnostics. Semantic gap analyses, brand clustering, and competitive positioning may yield different results depending on the embedding model used. Consequently, GEO workflows should avoid assuming embedding interchangeability and instead evaluate visibility using the same or closely aligned embedding models as the target LLM.
Third, the higher agreement observed in paraphrased and domain-specific texts indicates that semantic redundancy and paraphrase coverage can improve robustness. Content that expresses key ideas using multiple formulations is more likely to be semantically discoverable, even when embedding models differ in training objectives or representation geometry.
Finally, overlap at top-k and rank-based metrics provide practical tools for monitoring AI visibility drift. As embedding models evolve, these metrics can detect changes in how content neighborhoods shift, enabling organizations to proactively adjust content strategies and maintain visibility within generative search and answer engines.
Embedding alignment determines how consistently content is interpreted and retrieved across AI systems. Higher alignment increases the likelihood that content appears in relevant AI-generated answers and retrieval results across platforms.
Not always. While modern embedding models show strong overall agreement, differences in local neighborhood structure can affect clustering, similarity ranking, and semantic gap analysis, especially across domains.
Agreement@K measures overlap in nearest neighbors, capturing local semantic consistency, while rank correlation assesses global similarity ordering. Together, they provide a robust, task-agnostic comparison framework.

