The Client
Folio Wallet is a London-based digital wallet app for storing personal documents such as IDs, passports, payment cards, and medical records.
At the start of the project, Folio already had:
- A live website
- Presence on third-party platforms like social media, Reddit, and Trustpilot
What they didn’t have was measurable visibility inside large language models, specifically, being mentioned or cited when users asked ChatGPT relevant questions in their category.
The Timeline
Phase 1: Baseline & Testing (Aug 5 – Sep 10)
We ran initial tests across a wide range of prompts. It confirmed two things:
- There was no accidental or residual visibility.
- Any future movement would be attributable to the work done.
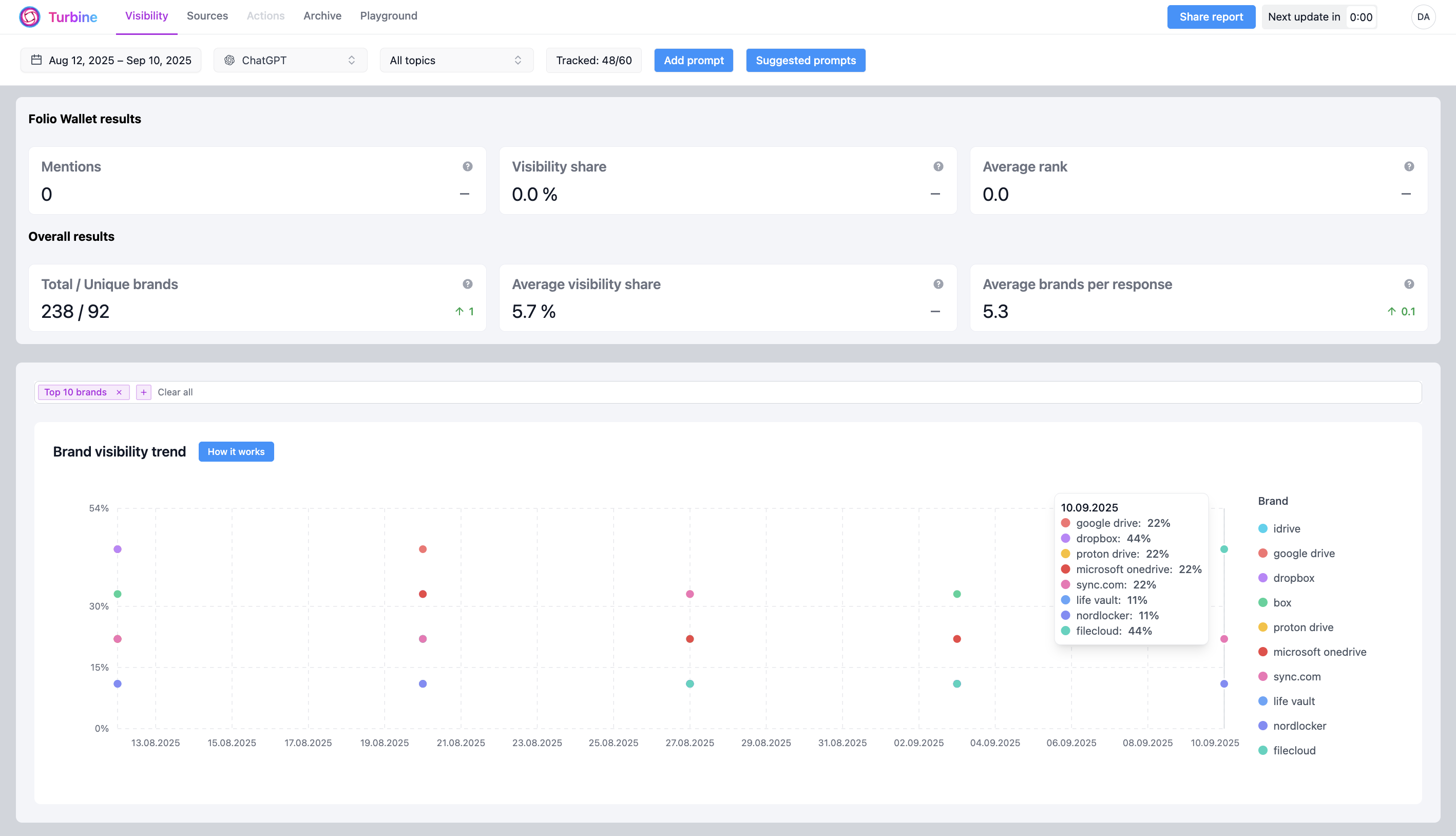
Result: 0% visibility. Folio did not appear in model outputs.
Phase 2: Setup & Prompt Strategy (Sep 11 – Sep 17)
We started with two fundamentals:
- Technical accesibility. Ensured the site was properly accessible for LLMs.
- Prompt set discovery. We built and validated a prompt set that could be tracked consistently over time.
We deliberately looked for prompts at the intersection of:
- Folio’s real product features
- Topics valuable for the brand narrative
- Areas where competitors appeared, but Folio didn’t (yet)
That intersection became the core prompt set we tracked going forward.
>> We describe the general methodology for building prompt sets here.
We also chose ChatGPT as the primary model to measure. While AI visibility work can create spillover effects across multiple models, strategies differ by model. Given ChatGPT’s current query volume, we treated it as the reference point.
Result: The initial setup and technical fixes resulted in the first 18% of visibility share for the chosen set of topics and prompts.
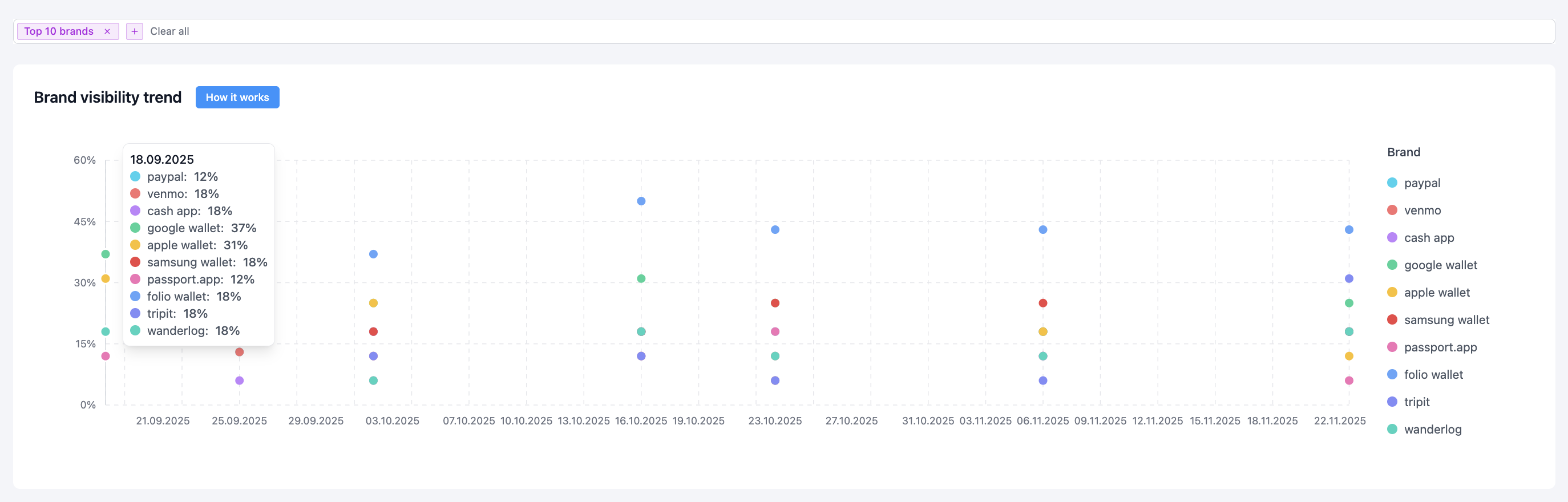
Phase 3: Core Optimization (Sep 18 – Nov 22)
This was the main execution phase.
We focused on three core thematic clusters:
- Security
- General document storage
- A new niche Folio wanted to win: storing tickets and personal documents in one place
What we did:
- Updated existing content (metadata, page structure, FAQ blocks)
- Created new content to close clearly identified semantic gaps
Results:
- Week 1: 20%
- Week 2: 37%
- Week 3: 50%
- Following month: stabilized at 43% visibility share
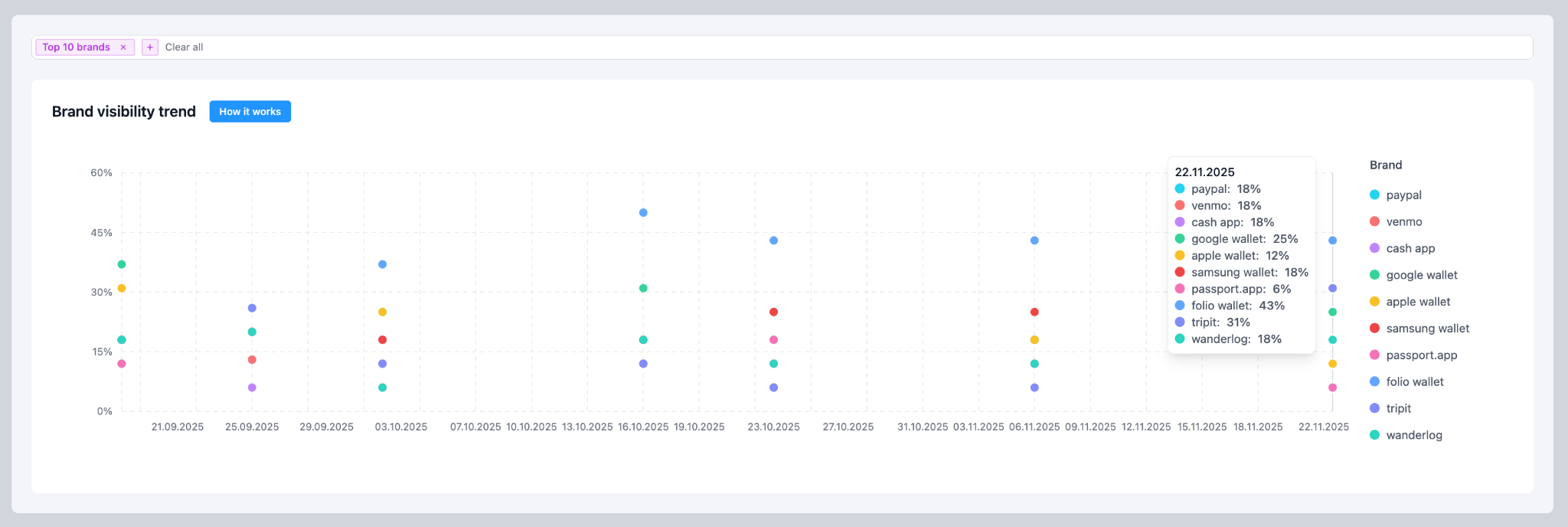
Phase 4: Stabilization Check (Nov 25 – Dec 14)
For three weeks, we made no changes at all.
We simply observed whether visibility would hold.
Result: it did. The gains were not short-term fluctuations.
Why This Worked
Optimizing for AI search is, at its core, about systematically working through the topics (and prompt variations) where a product wants to appear—and then doing the work required to actually show up there. Ultimately, this leads to more users for the product: more traffic from chatbots and more self-reported customers who say they discovered the product through model recommendations.
Technical setup and reputation matter, but the main body of work is updating existing content and proposing new content so that models start associating the product with the desired topics and are more likely to surface it in responses.
Turbine’s Approach to AI Search Visibility
Most tracking tools on the market simply monitor how often a product appears for a predefined list of prompts. Most SEO and marketing agencies base their recommendations on personal experience and observation, which is why their advice often differs. We take a different approach.
Since large language models ultimately see the world through vectors, we can use mathematics to estimate in advance which texts are likely to appear for a given topic or prompt. Yes, there are fluctuations. By nature, LLMs may show different results from one day to the next, and hallucinations do occur. But with regular tracking, it is possible to distinguish a one-off result from a repeated pattern. Even accounting for model instability, movement from zero visibility to the 30–50% range is clearly measurable.
What We Did in Practice
For every topic (and for every prompt within that topic) we followed the same procedure.
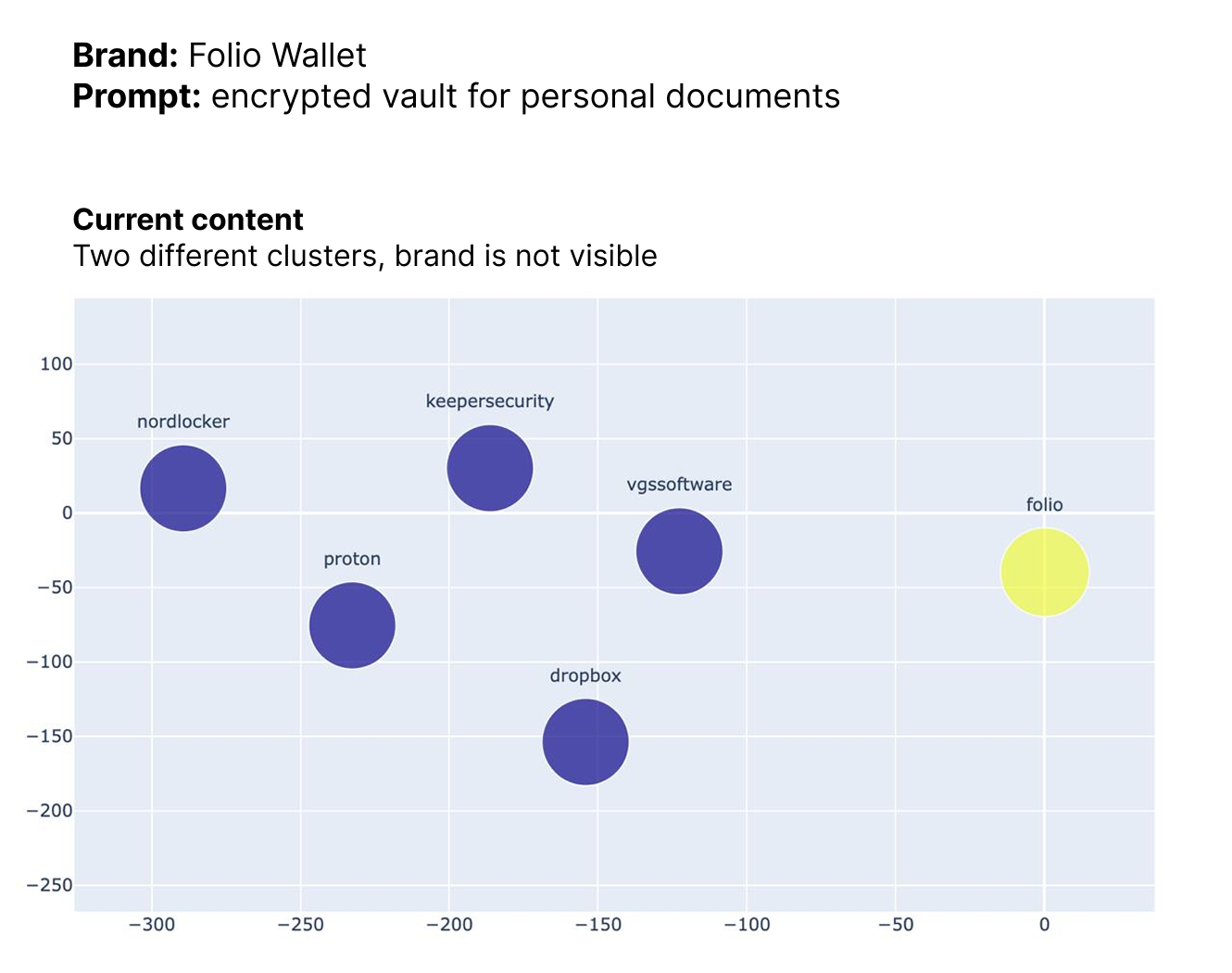
Below is a simplified example based on a single prompt: "encrypted vault for personal documents".
Initial Assessment
At the start, Folio Wallet and the brands already appearing in responses were located in different semantic clusters. Existing brands occupied one cluster (blue), while Folio sat in another (yellow). In this state, Folio had a low probability of being shown as an answer.
Content Creation
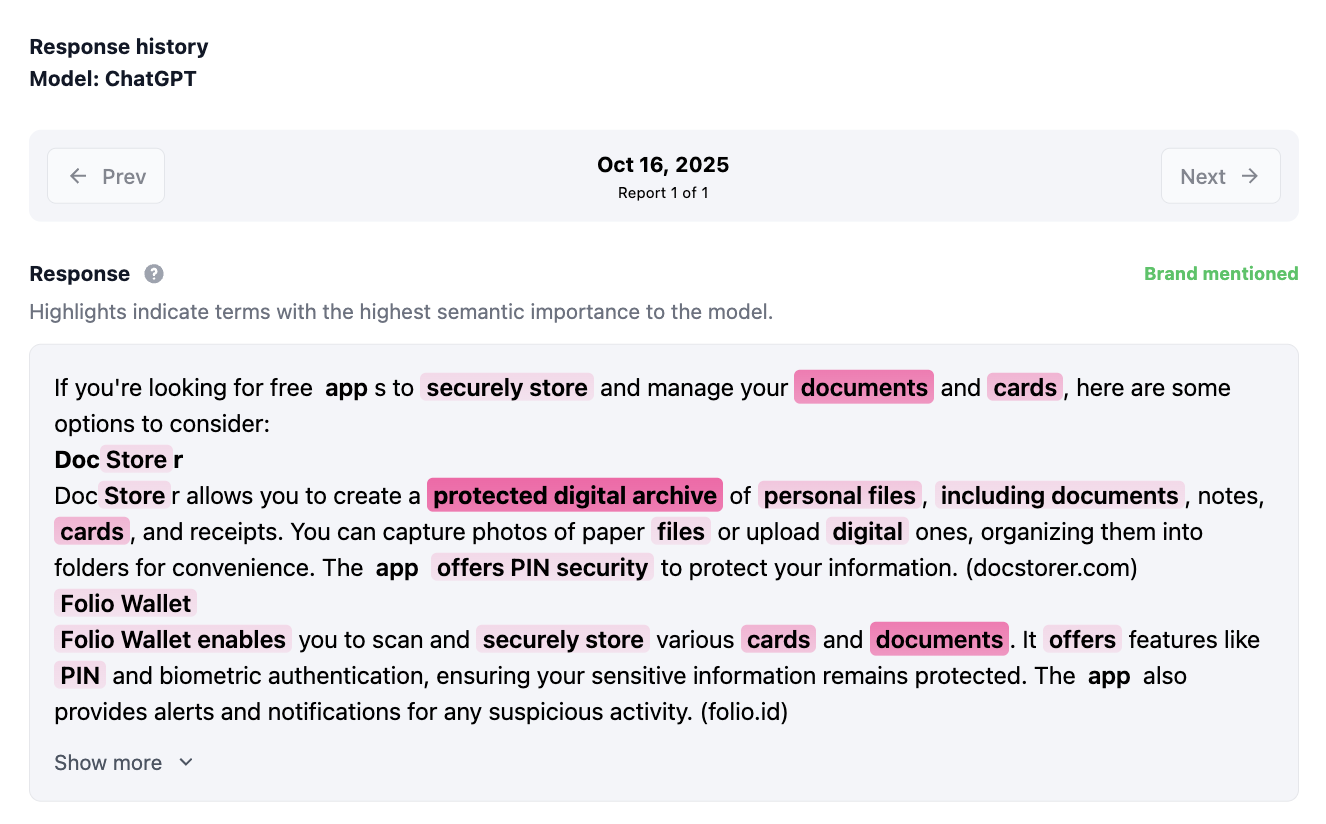
We use standard content guidelines (structure, relevance, length, etc.), but the most important input is semantics as seen by the model itself. Even in Turbine’s free reports, you can see a preview of this approach: model answers are annotated with semantic entities, showing how the LLM interprets the text. This already provides a clear signal for how new content should be constructed.
The same logic can be explored using Turbine’s semantic keyword extractor. It returns keywords as the model understands them and groups them into semantic clusters.
>> Try Semantic Keyword Extractor
Evaluation Before Publishing
On the previous step we created new content for Folio for each prompt where the brand aimed to appear. In a traditional approach, the next step would be to publish the content and then check whether it worked or not. With our approach, however, we can estimate in advance how strong the chances are for a given text to appear in model results.
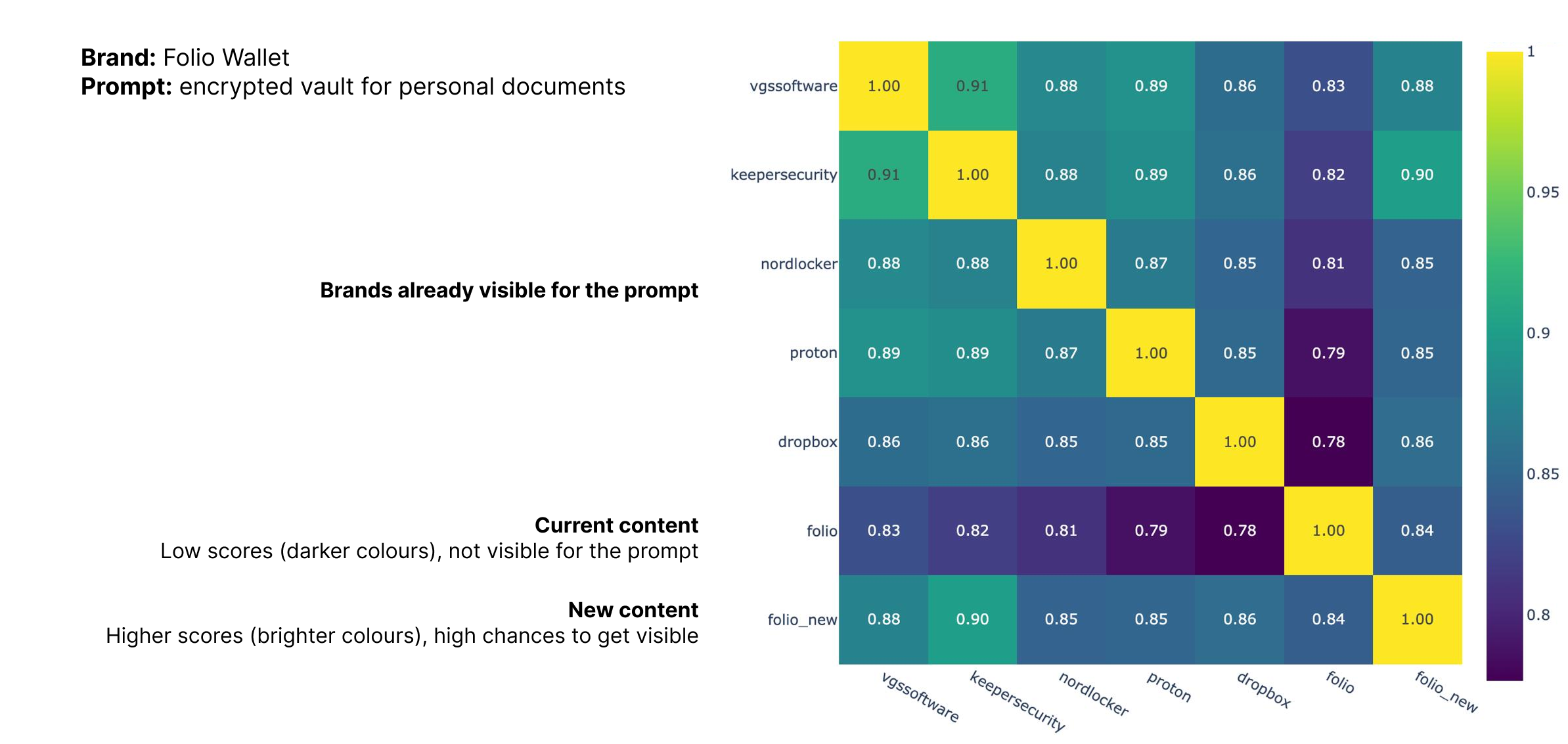
For example, for the prompt discussed above, we built a heatmap: the brighter the color, the closer the text is to those already being surfaced for that prompt (shown in the first five rows).
You can see that in Folio’s initial state (the second-to-last row), semantic similarity scores did not exceed 0.84, which in this case was not sufficient to be included in results. With the new version (the last row), similarity scores reached 0.9 - on par with brands that were already being shown for the same prompt.
Evaluation after publishing
The final step was empirical validation: publishing the content and monitoring AI visibility for the same prompt. After publishing the updated content, we observed that it was in fact cited by the model, and Folio began appearing consistently in the results.
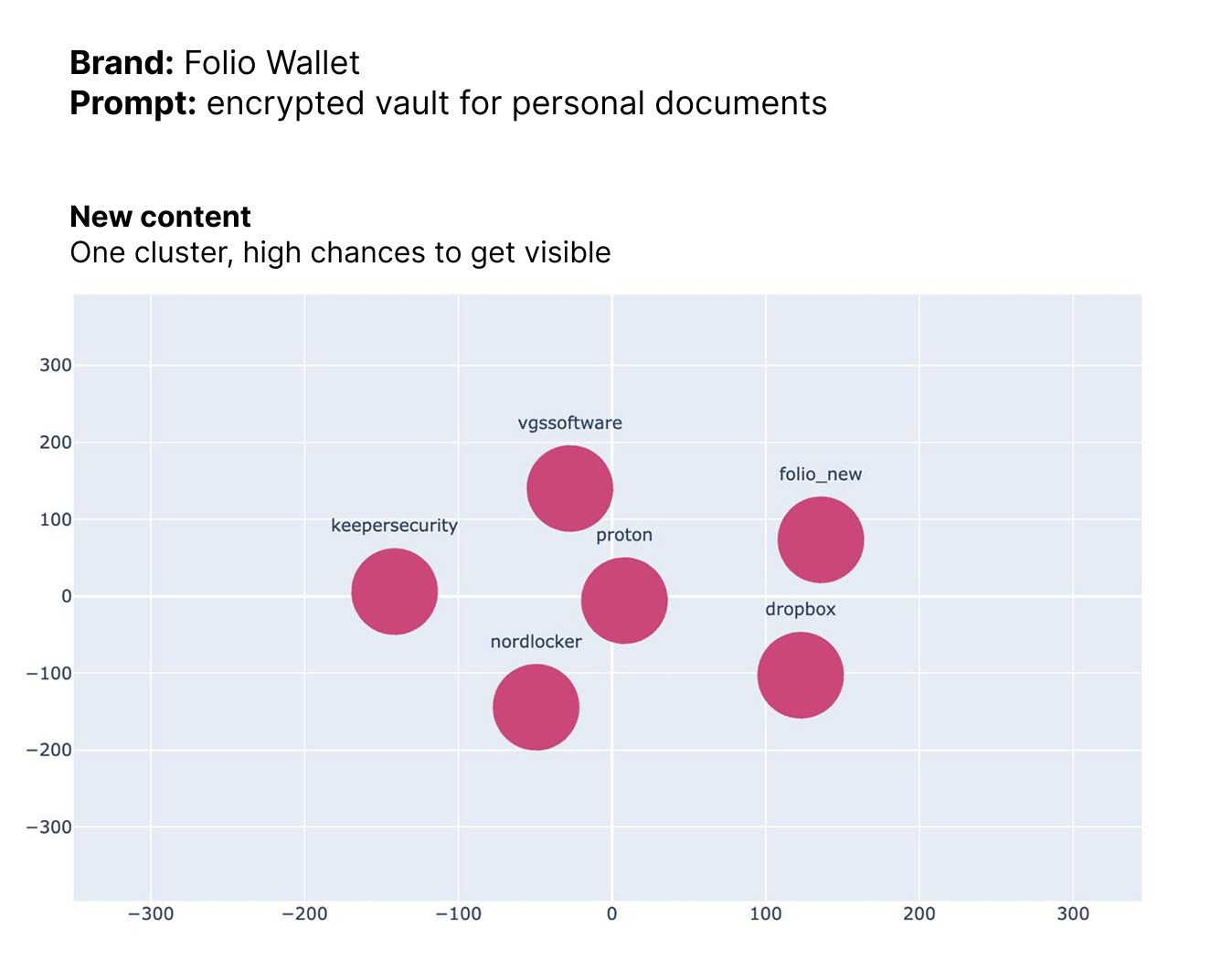
We then verified this again using semantic clustering. When this content was taken into account, the model placed Folio in the same cluster as the brands already visible for that prompt (highlighted in pink).
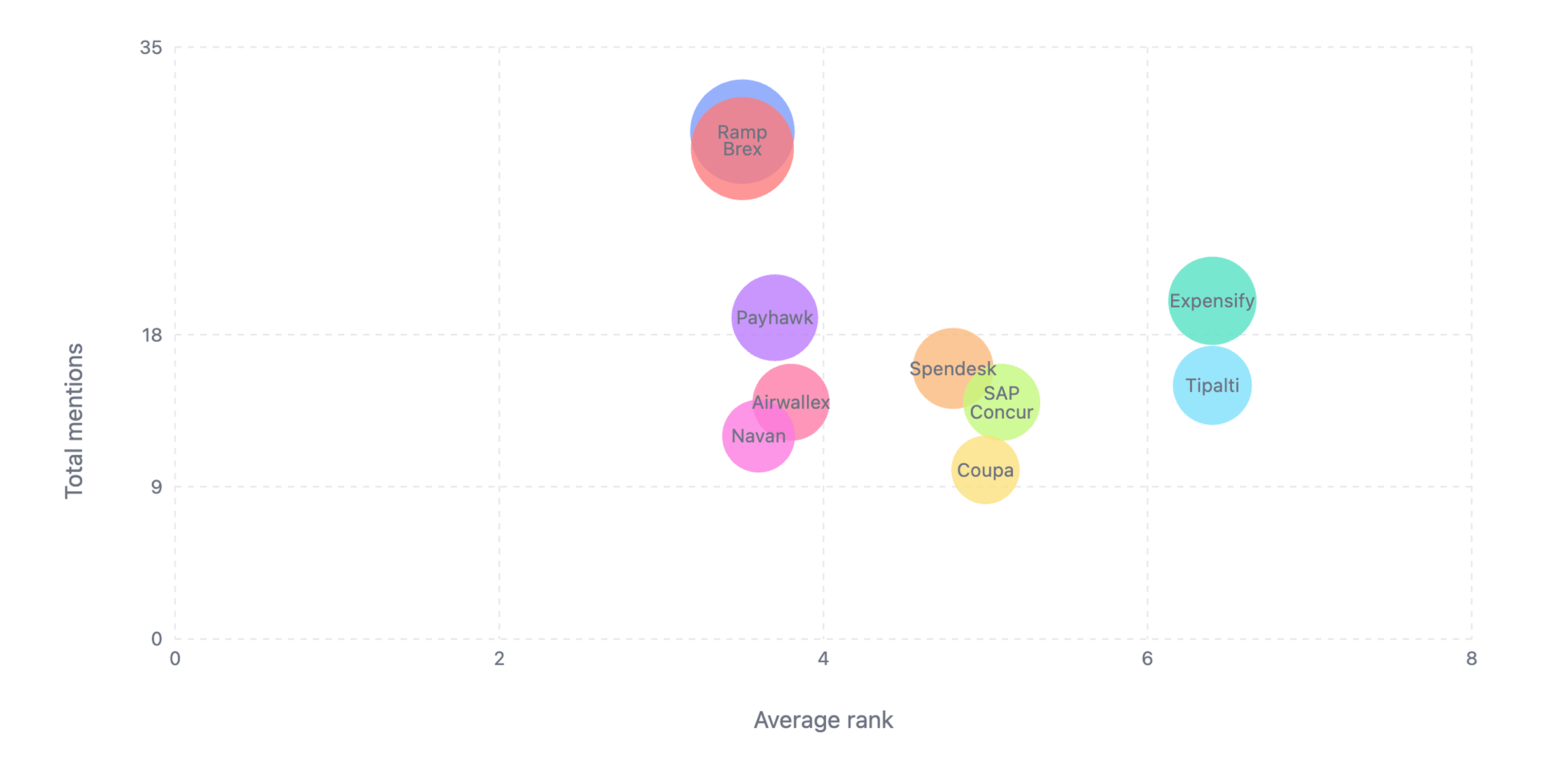
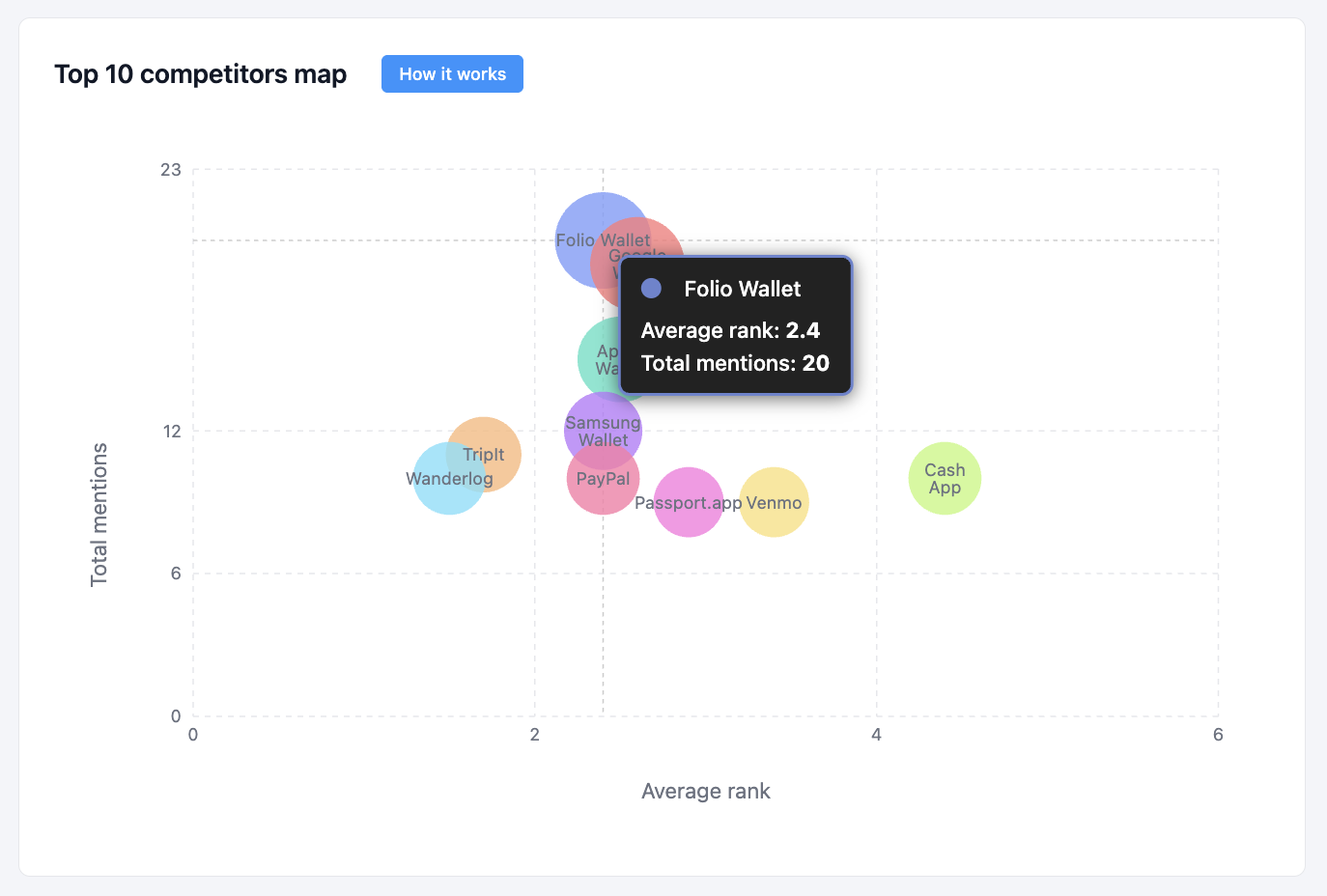
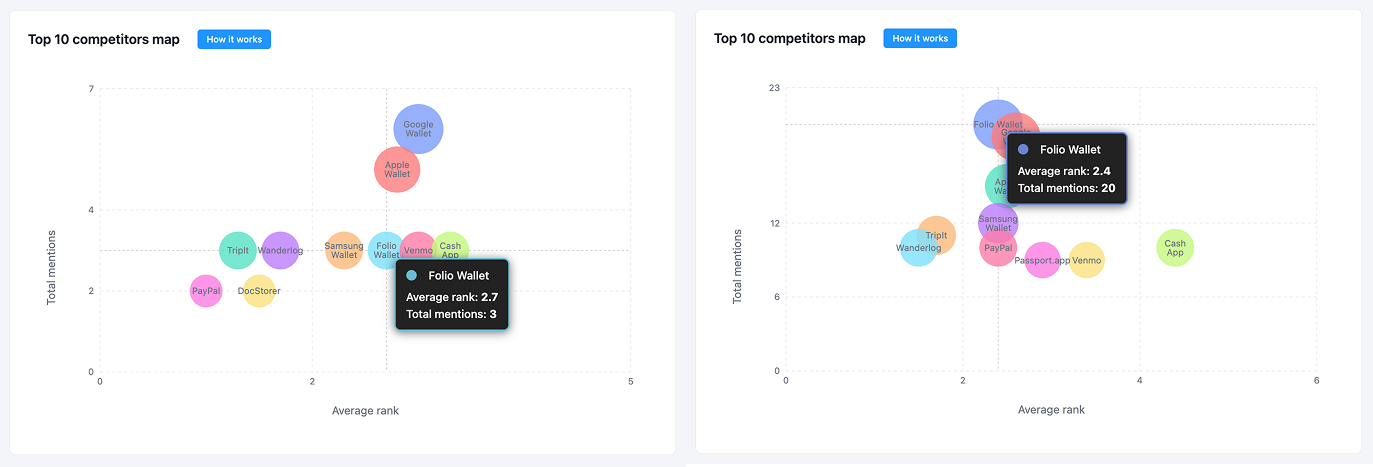
Overall Results
After Folio moved from low visibility to a leading position in its category. A clear narrative was established and reinforced.
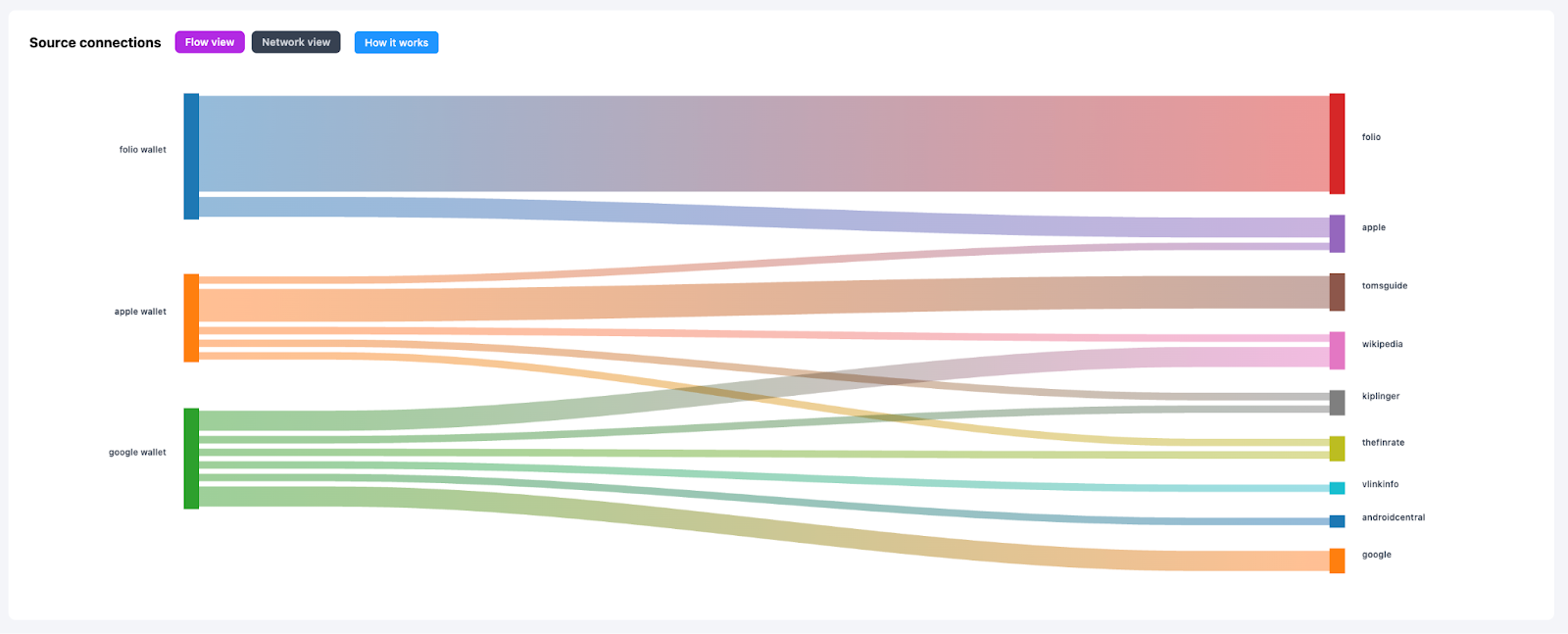
The Folio website became a primary citation source when models talk about Folio.
Strategically, Folio:
- Secured its core position in security wallets and digital document storage
- Successfully entered and held a new space: all-in-one travel and personal documents
All of this while competing with products like Google Wallet and Apple Wallet, as well as long-established players in the travel segment.
.png)